Hint: The Answer Impacts Clinical Analysis / Submission
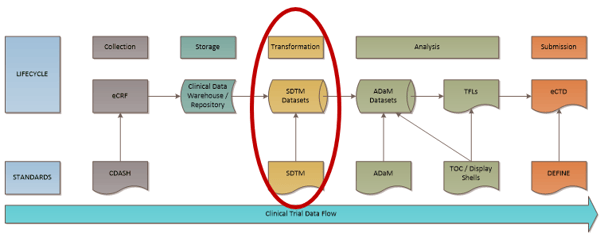
The nature of the clinical trials data flow is well established with standardized roles & processes. However, nuances exist with the process flow that can have downstream effects on submission timing!
The responsibility of creating the statistical analysis plan and analysis artifacts clearly falls to statisticians and statistical programmers, and the collection and cleaning of data falls to the data managers. But the question remains, who's in charge of creating SDTM datasets?
Is it data management? Statistical programmers? Or is it someone else? Perhaps a data standards group, or is it something that should be automated?
When Data Management Create SDTM datasets
When Data Management is done right, the output will be SDTM-compliant! Data managers can spend more time managing their data and getting that to the highest quality leaving stats programmers to use their knowledge and ability in statistics to produce analysis datasets and TFLs. A specialized team able to focus purely on SDTM datasets and with time to keep up with changes to any standards and a deep knowledge of SDTM and submission packages would be a definite advantage. And it would eliminate the need for statistical programming work due to less-than-perfect design of the eCRF and standards implementation on Data Management's part. SDTM programming is data programming, not analysis, so it is closer to Data Management. Many SDTM programmers would not program in ADaM (for example) or program TFL's. There is a difference in understanding of the data when between programmers from data management and statistical programming.
Why Statistical Programmers are creating SDTM
Typically it falls under Stats programming as there is some amount of transformations needed for programming and they are generally the ones staffed with competent SAS programmers able to create the datasets. This is very much down to the individual companies again, but the main reason is agility in programming and an overall ability to program (in SAS currently) based on standards and specifications for the creation of SDTM. It likely matters where in the chain the define.xml output is generated as the same programmers may be required for that task in a different part of the process!
Data Managers tend to pick up on many aspects that are missed by programming team due to their understanding of the data and standards.
How size and scale of the company affects SDTM Responsibility
Projects like define.xml output reside in Stats Programming at small-to-mid scale companies. But at large pharma enterprise scale, Data Management is brought in to provide standards and processes that span dozens of trials going on at hundreds of sites worldwide. The regulatory burden for clinical trial data security, privacy, and code validation is immense at the multinational pharma level. That burden is what Data Management is made to handle, freeing statisticians to do statistics.
Ultimately we encourage d-wise clients to look at SDTM Programming as a team effort and a bridge between data management and statistical analysis of clinical trials. The great thing about SDTM programming is that it sits between DM and Stat programming. It requires a mindset from both sides, but does not seem to belong to any one department. If a company can afford, the best solution is to create a specialized SDTM group to ensure accuracy and compliance.
The department that has the right people who are educated, trained and able to do the work. Depending on the size of and organization of the company that could be any of your choices and even a vendor. At the end of the day you want an end product of SDTM programming so the right people, equipment, facility and process is the key, not the name of the department.
Automation and the future
Perhaps a better question is not “Who SHOULD do this?" but rather "How should we create SDTM data?" or even "Should we create SDTM data at all”? But that answer would require a total change of how things have always been done and a significant shift in mindset! There is a thought that SDTM should be driven by a well-defined Metadata Repository (MDR) for automation of standards within data management. Some of the big pharma companies have attempted to do that with mixed results.
What the people say
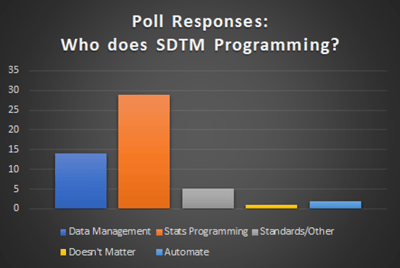
A recent poll on LinkedIn suggested that stats programming was the place to do SDTM programming with 57% of respondents voting that way and only 27% for data management, but the cases for data management seem stronger despite those numbers. It seems like it is done in statistical programming because that is just where it is done for that particular company.