

Whether you are new to a SAS Grid based environment, or you have been using it for some time, the chances are that in a life science environment you are not making the most of it. The biggest change you've likely made is to use SAS Studio or Enterprise Guide and then continue programming as normal...
It begs the question, why would you change? Datasets used in clinical programming are typically small, processing only usually takes a few seconds or minutes, so why go to the hassle of learning how to run slices of code in parallel? Why take steps to optimize what doesn't seem to need optimizing?
Perhaps it is the case that you didn't realize some of the habits that have formed over many years, you have had to program and manage your code to manage the risk of system bottlenecks or to ensure a clean start to your environment (programs reset each time they are run). Maybe you have had to manually create driver files to execute batches in the right order (and be able to split up into smaller runs). How did you guarantee of reproducibility of what was delivered? Then there is the manual tracking and verification that QA processes have been followed...
Now we are in a much stronger place to understand how to optimize those processes, that code. Why not optimize execution automatically (parallel vs sequential)? What about creating outputs that are ready to consume rather than just ascii files? Have you ever thought about creating an ecosystem to support the registration of dependencies prior to execution enabling navigation and drill down as well as supporting the parallelization of batch execution?
It's time to try something new.
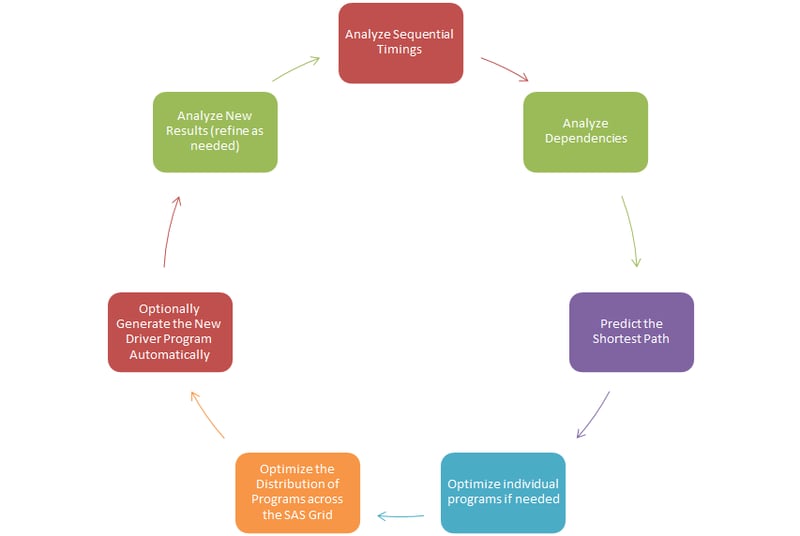
Start by reducing the critical path program execution cycle time! The easy thing to do when you have a SAS Grid is to continue executing programs in the same way that they always have been. But that will not harness the power at your disposal. It will not deliver the return that you have been promised.
To make the leap, start by analyzing sequential timings and dependencies, predict the shortest path, optimize individual programs if needed. Then optimize the distribution of programs across the SAS Grid and optionally generate a new driver program automatically and analyze any new results (i.e. refine as needed). Rinse and repeat!
You can get there with the help of d-wise as we help to create a batch submission tool to queue jobs based on dependencies (inputs & outputs). The d-wise team has the expertise to educate large scale programming teams in parallel programming and advanced techniques to take advantage of Grid power. This becomes more critical when you add modelling and simulation or real world data activities into the mix, as with those "big data" come significant ongoing processing challenges.
For more information on optimizing your Grid code take a look at one of the d-wise PhUSE papers (PhUSE 2016 | PhUSE 2017) that to go into more detail, or talk to a d-wise representative to see how you could optimize your Grid environment.
