

Authors:
Jon Horton, VP of Delivery and Quality
Chris Decker, VP Life Sciences
In January of this year a major sponsor had to pull back their application due to data integrity issues and the inability to provide traceability for their primary analyses. Companies need to realize that the FDA has significantly increased their scrutiny over ensuring the traceability and integrity of clinical data and be diligent about assessing their internal processes and technology. In this blog, we’ll take a look at the focus on data integrity, how to meet current regulations, and industry gaps.
Want to read more? This blog is taken from a paper our team wrote for PHUSE. Read the paper or watch the presentation. Paper | Presentation
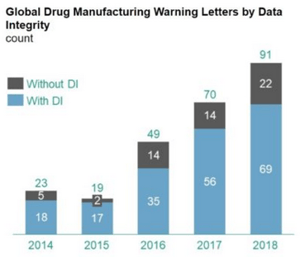
For decades the FDA has identified data integrity issues during inspections, with the number of findings steadily increasing as the industry continues to embrace the use of computerized systems and new technologies.
When considering the safety and efficacy implications, however, it should be of no surprise that the FDA and other Health Authorities are placing such importance on the integrity of the data being produced, stored, analyzed, and reported out of these systems. It’s important to remember that, at the end of every clinical data point, there is a patient. A mom, a dad, a brother, sister, son, daughter, aunt, uncle, grandma, and grandpa who are placing their trust, and possibly their life, in the hands of a Life Science company’s research, protocols, processes, and computerized systems…all with the hope that their involvement can lead to improved quality of life for themselves or future mankind.
To ensure the people, processes, products, and systems that contribute to the release of approved medicines do so in a way that ensures the safety, efficacy, and integrity of the medicines, Health Authorities like the FDA define regulations, e.g. 21 CFR Parts 11, 210, 211, and 212, that must be followed.
However, despite the identification and creation of data integrity related regulations, regulators initially struggled with the transition from a paper-based industry to a computerized industry. In recent years though, regulators have received the training necessary to inspect systems with an eye for data integrity gaps and to appropriately challenge perceived deficiencies.
The scarcity of data integrity related findings pre-2014, followed by steadily increasing rates of data integrity findings since is a clear signal that Inspectors are both trained and mandated to search out data integrity gaps associated with the creation of data, storage of data, analysis of data, and reporting of data. Examples of recent data integrity related findings illustrating this point can be found in the FDA’s December 2018 publication of “Data Integrity and Compliance With Drug CGMP Questions and Answers, Guidance for Industry:”
HOW DO YOU MEET DATA INTEGRITY REGULATIONS?
The ALCOA + requirements, a central tenet of the FDA’s CGMP practices, outline the nine (9) core attributes of data integrity: Attributable, Legible, Contemporaneous, Original, Accurate, Complete, Consistent, Enduring, and Available.
While the 9 data integrity attributes listed above seem simple in nature, the implementation of disparate, standalone systems that lack the integration capabilities necessary for seamless data sharing have made achieving compliance challenging and complex.
However, regardless the complexity or challenge associated with achieving compliance, compliance is nevertheless required to compete in this space. In our opinion, the fastest, least expensive, and best path forward for achieving compliance is to leverage the available Life Science SaaS/PaaS/IaaS offerings that meet your organization’s needs, qualify the vendor in accordance with considerations listed in the FDA’s 2017 draft guidance validate the use of the vendor’s product within the framework of your processes and workflows, and ensure ALCOA + attributes are accounted for when activities performed are governed by regulatory requirements of a Health Authority.
Quality MIRAGE and Industry Gaps
Emperor’s Clothing
In the famous story by Hans Christian Andersen, “The Emperor’s New Clothes”, two weavers convince the Emperor that he is wearing an invisible set of clothes that only the most privileged can see. However, he is naked and embarrassed in front of his whole kingdom.

This feels very similar to how our industry has been convinced they have implemented compliance through documents, processes, and checkboxes. We develop processes with significant manual intervention and human interpretation and expect it to lead to a high-quality deliverable at the end. We throw out many acronyms – SDLC, IQ/OQ, UAT, PQ, SOP, etc. – and expect that if we just write all these documents and check all the associated boxes then poof – we have quality!
The reality is that this is mirage. We end up creating a myriad of hidden issues despite all this documentation and checkboxes. There are so many examples of this within our clinical data lifecycle from the installation and qualification of a system to the development of code to generate the data to the review of our analysis results. Let’s use one example.
The figure below is a picture of our process for generating data. A person develops a spreadsheet that attempts to describe the rules and algorithms that must be used to generate a derived data set and someone else (most likely people of a different native tongue) reviews it - CHECKBOX. Then two different people, again most likely people who write in a different native language program it separately, so we have ‘matching’ data – CHECKBOX. Then another person checks the final data set – CHECKBOX. All this independent work and checking must lead to a high-quality product – right? NO! While introducing these steps might provide us more opportunity to catch problems, it gives us a false sense of traceability and compliance because we are checking the box that we have specifications and better quality data and not focusing on the real need.
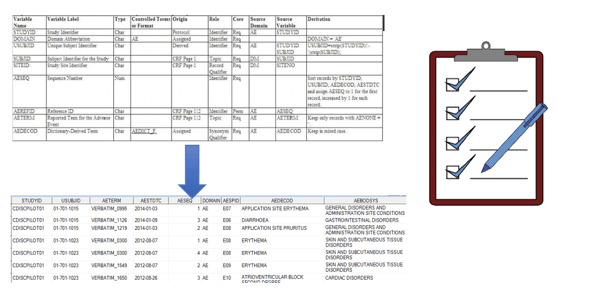
Industry Gaps
As described above, the scrutiny of regulatory audits has increased significantly within the Biometrics space over the last 5 years. This has led to a plethora of findings that sponsor companies have had to address to ensure compliance. In the past clients have attempted to close those gaps through a mixture of implementing siloed technology and defining processes that are supposed to be followed. Unfortunately, gaps in technology, staff turnover, and stress filled deadlines have led to shortcuts and errors in following these processes.
Recently, a d-wise client was issued a warning from the FDA which identified significant findings within the biometrics data flow space. These issues led to delays in submission, millions of dollars of remediation, and a lack of confidence internally and from regulators. Through compliance assessments across a range of clients we have identified a set of findings in key areas. Most of our client are surprised and sometimes shocked when they are informed of the gaps they have in their technology and processes to ensure compliance and integrity. This is just a sample of those findings…
Manual processes to set up and manage users led to errors over 25% of the time
Complex security models are unmanageable and inaccurate
Users access the system after leaving the company
Blinded users gain access to sensitive data putting validity of results in jeopardy
Case Study: Building Solutions to increase Data Integrity
Clients engage d-wise to design, build and implement solutions to support their clinical computing and ensure they have end to end compliance.
Example Capabilities
Recently, d-wise built a solution for a customer where the highest priority was to ensure data integrity and compliance. In collaboration with the key business stakeholders, the solution was designed, built, and deployed with the following key components.
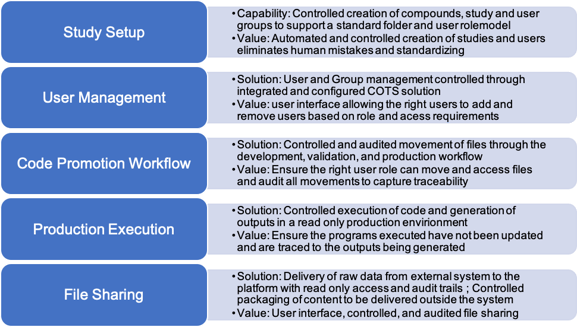
The solution minimized the disruption to the business by making it accessible within an environment very familiar to the end user and hiding the technology plumbing under the covers (versioning, auditing, etc.). There are many approaches to implementing fir for purpose solutions that can control and manage compliance by using COTS and open source technologies that can be integrated and configured.

Conclusion
The key to implementing the components above is to focus on simplifying your overall needs and developing and/r configuring tools that can automate and provide a robust framework for compliance.
The FDA is becoming more sophisticated in identifying and enforcing data integrity gaps. As technology advances and continues to be adopted it’s imperative that you understand how to engage properly with 3rd party vendors to have a complete and holistic solution. We also need to understand the regulatory drivers behind the adoption so we can implement compliant solutions that can ensure integrity of our most important asset – our data.
We must evaluate whether our current quality paradigm is actually focused on the right thing and leading to the quality we expect. Technology exists today that can solve these issues if we just understand and adopt it. It is possible to build a compliance framework that balances ability for users to get the job done with the data integrity checks that must be in place to ensure you have compliance required.
